
View WebSci 2020 Presentation in a new tab
The WebSci 2020 virtual conference has a special theme on Digital (In)Equality, Digital Inclusion, Digital Humanism the first day of this virtual conference. This will gave us the chance to show the initial findings from our linking of freely available Augmentative and Alternative Communication (AAC) symbol sets to support understanding of web content.
There are no standards in the way graphical AAC symbol sets are designed or collated other than the Blissymbolics ideographic set that was “standardized as ISO-IR 169 a double-byte character set in 1993 including 2384 fixed characters whereas the BCI Unicode proposal suggests 886 characters that then can be combined.” Edutech Wiki.
Even Emojis have a Unicode ID, but the pictographic symbols most frequently used by those with complex communication needs do not have an international encoding standard. This means that if you search for different symbols amongst a collection of freely available and open licenced symbols sets you find several symbols have no relationship with the word you entered or the concept required.
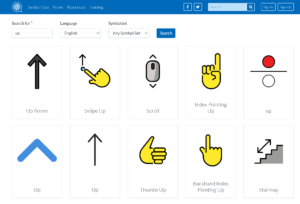
This lack of concept accuracy means that much work has to be done to enable useful automatic text to symbol support for web content. Initially there needs to be a process to support text simplification or perhaps text summarisation in some cases. Then keywords need to be represented by a particular symbol (from a symbol set recognised by the reader), that can be accurately related to the concept by their ISO or Unicode ID. Examples can be found in the WCAG Personalization task force Requirements for Personalization Semantics using the Blissymbolics IDs.
The presentation at the beginning of this blog will illustrate the work that has been achieved to date, but it is hoped that more can be written up in the coming months. The aim is to have improved image recognition to assist with the semantic relatedness. This automatic linking will then be used to map to Blissymbolics IDs. It is hoped that this will also enable multilingual mapping, where symbol sets already have label or gloss translations.

However, there still needs to be a process that ensures whenever symbol sets are updated the mapping can continue to be accurate as some symbol sets do not come with APIs! That will be another challenge.